Yapay Zeka'da Bağımsız Yargı ve Nature'dan Büyük Dil Modellerine "Peer Review" Çağrısı


Nature dergisinde yayınlanan önemli bir makalede DeepSeek'in R1 modeli, hakemli denetimden geçen ilk büyük dil modeli oldu. (DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning - https://www.nature.com/articles/s41586-025-09422-z) Aynı gün Nature Editorial, "Bring us your LLMs: why peer review is good for AI models" başlıklı görüş yazısını paylaşarak "LLM'lerinizi Bize Getirin: Hakem Değerlendirmesinin AI Modelleri İçin Faydaları" çağrısını yaptı.
Bu gelişme, yapay zeka sektöründe önemli bir dönüm noktası olabilir. Aslında son 3-4 yılda geldiğimiz bu nokta düşünüldüğünde, bu durumu asıl sahip olduğumuz bilimsel paradigmaya geri dönüş olarak da algılayabiliriz.
Şirketler büyük dil modellerini kapalı kaynak tutarak sadece teknik raporlar ve birçok detaydan arındırılmış makaleler yayınlıyorlar. Nature editorialinin belirttiği gibi, insanlığın bilgi edinme şeklini hızla değiştiren en yaygın kullanılan büyük dil modellerinin hiçbiri bağımsız hakem değerlendirmesinden geçmemiş durumda.
Şimdiye kadar yapay zeka ve teknoloji şirketleri, model yarışında kendi hazırladıkları teknik raporları benchmark testleri üzerinden sunarak ilerlediler. Bu süreçte:
Herhangi bir peer review (hakem değerlendirmesi) süreci olmadan çalışmalarını paylaştılar
Model parametrelerini halka açık hale getirmediler
Çalışmanın tekrarlanmasını mümkün kılmayacak kadar az detay içeren eğitim metodolojileri kullandılar
Benchmark manipülasyonu yaparak modellerini olduğundan daha yetenekli gösterdiler (örnek sorular ve cevaplar içeren verilerle eğitim)
Güvenlik değerlendirmelerini ihmal ettiler (siber saldırıları önleme, önyargıları azaltma gibi)
Tek yönlü bilgi akışı ile sadece kendi seçtikleri bilgileri paylaştılar
Bağımsız dış denetimden kaçınarak kendi ödevlerini kendileri değerlendirdiler
Doğrulanamayan iddialar ve hype ile sektörü yönlendirdiler
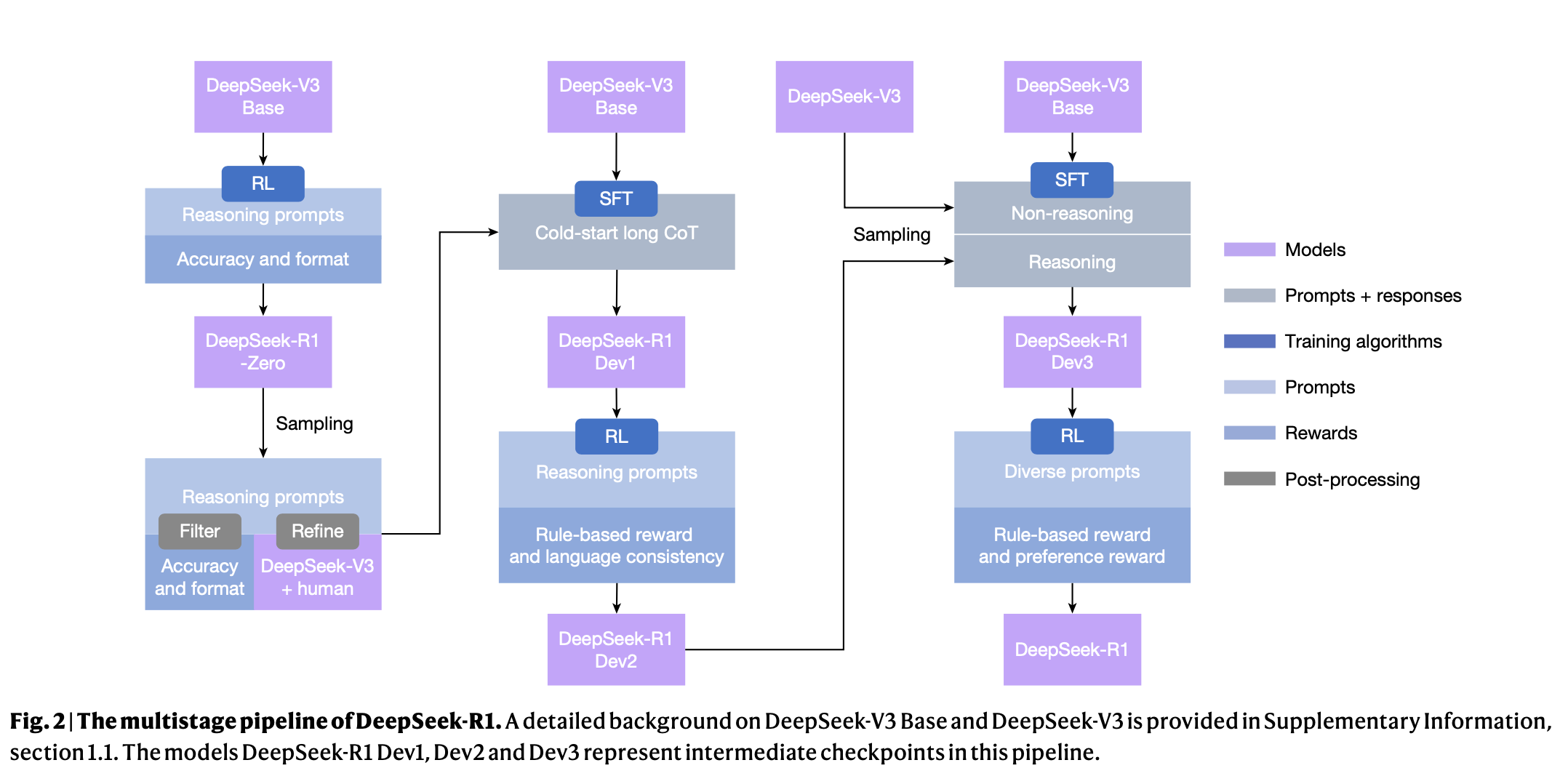
Nature editorialinde vurgulandığı üzere, R1 modelinin hakem değerlendirme süreci kritik iyileştirmeler sağlıyor;
Benchmark Manipülasyonu Sorunu: Hakemler, DeepSeek'in model eğitiminde veri kirliliği (data contamination) olup olmadığını sorguladı. Şirket, bu riski azaltmak için aldığı önlemlerin detaylarını paylaştı ve model yayınlandıktan sonra geliştirilen yeni benchmark'larla ek değerlendirmeler ekledi.
Güvenlik Değerlendirmesi: Hakemler, modelin güvenlik testleri hakkında yetersiz bilgi olduğunu işaret etti. Bunun üzerine DeepSeek, AI güvenliği değerlendirmeleri ve rakip modellerle karşılaştırmaları içeren yeni bir bölüm ekledi.
Sektörde de bir farkındalık artışı gelişiyor (yada zaten farkındalardı fakat bu pratiği uygulamaya teşvik oluyorlar), firmalar dış denetimin değerini anlamaya/değerlendirmeye başlıyor:
OpenAI ve Anthropic geçen ay birbirlerinin modellerini test etti ve geliştiricilerinin gözden kaçırdığı sorunları tespit etti
Mistral AI, modelinin çevresel etkilerini dış danışmanlarla birlikte değerlendirdi
Google'ın Med-PaLM modeli Nature'da yayınlanarak, tescilli modeller için de hakem değerlendirmesinin mümkün olduğunu gösterdi.
“Peer reviews relying on independent academics is a way to dial back hype.”

Nature bu çağrısında sayfanın tam ortasında şöyle diyor;
Bağımsız Akademisyenlere Dayalı Hakem Değerlendirmesi, AI Sektöründeki Abartıyı Azaltmanın Bir Yoludur.
Doğrulanamayan iddialar, bu teknolojinin ne kadar yaygın hale geldiği düşünüldüğünde toplum için gerçek bir risk oluşturuyor.
DeepSeek-R1'in Nature'da yayınlanması ve editöryal çağrısı, AI geliştirme süreçlerinin geleneksel bilimsel standartlara uygun hale getirilmesi gerektiğini vurguluyor. Hakem değerlendirmesinin, şirket sırlarına erişim anlamına gelmediğini, ancak iddiaları kanıtlarla destekleme ve doğrulamaya hazır olma anlamına geldiğini savunuyor. Bu, sektörde şeffaflık, tekrarlanabilirlik ve bağımsız değerlendirme kültürünün yerleşmesi açısından kritik bir adım olarak görülüyor.
 | A guest post by
|